Activation Functions
Introduction
Activation functions are a component of neural networks they introduce non-linearity into the model, enabling it to learn complex patterns. Without activation functions, a neural network would essentially act as a linear model, regardless of its depth.
Key Properties of Activation Functions
- Non-linearity: Enables the model to learn complex relationships.
- Differentiability: Allows backpropagation to optimize weights.
- Range: Defines the output range, impacting gradient flow.
In this post I will outline each of the most common activation functions how they are calculated and when they should be used.
1. Sigmoid
The sigmoid function maps inputs to a range between 0 and 1.
Formula:
$$ \sigma(x) = \frac{1}{1 + e^{-x}} $$import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Example
x = np.array([-1, 0, 1])
print(sigmoid(x))
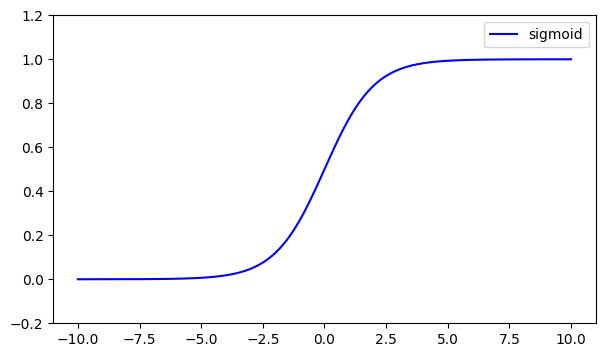
Use Case:
- Commonly used in the output layer for binary classification problems.
- Downsides: Prone to vanishing gradients for large positive/negative inputs.
2. ReLU (Rectified Linear Unit)
The ReLU function outputs the input directly if it’s positive, otherwise 0.
Formula:
$$ f(x) = \max(0, x) $$Python Implementation:
def relu(x):
return np.maximum(0, x)
# Example
x = np.array([-1, 0, 1])
print(relu(x))
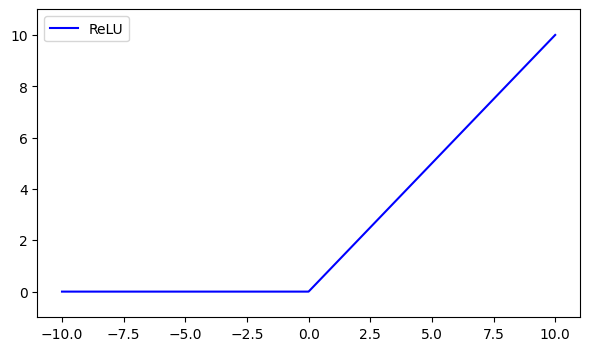
Use Case:
- Widely used in hidden layers due to its simplicity and efficiency.
- Downsides: Can lead to “dying ReLU” where neurons output zero for all inputs.
3. Leaky ReLU
Leaky ReLU mitigates the “dying ReLU” problem by allowing a small, non-zero gradient for negative inputs.
Formula:
$$ f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{if } x \leq 0 \end{cases} $$Python Implementation:
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
# Example
x = np.array([-1, 0, 1])
print(leaky_relu(x))

Use Case:
- A good choice when dealing with sparse gradients.
4. Softmax
The softmax function converts logits into probabilities, ensuring that they sum to 1.
Formula:
$$ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}} $$Python Implementation:
def softmax(x):
exp_x = np.exp(x - np.max(x))
return exp_x / exp_x.sum(axis=0)
# Example
x = np.array([1, 2, 3])
print(softmax(x))
Use Case:
- Used in the output layer for multi-class classification problems.
5. Tanh (Hyperbolic Tangent)
Tanh scales inputs to a range between -1 and 1.
Formula:
$$ \text{tanh}(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $$Python Implementation:
def tanh(x):
return np.tanh(x)
# Example
x = np.array([-1, 0, 1])
print(tanh(x))
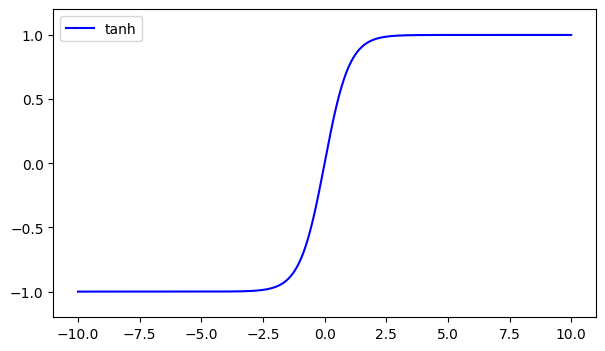
Use Case:
- Often used in hidden layers of recurrent neural networks (RNNs).
- Downsides: Prone to vanishing gradients.
Choosing the Right Activation Function
The choice of activation function depends on the task and architecture:
- Sigmoid: Binary classification.
- ReLU: Hidden layers in deep networks.
- Leaky ReLU: When ReLU suffers from dying neurons.
- Softmax: Multi-class classification.
- Tanh: For RNNs or when outputs need to be centered around zero.
Activation Functions in PyTorch
Here’s how to use these functions in PyTorch:
import torch
import torch.nn as nn
# Example: Using ReLU in a dense layer
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.Softmax(dim=1)
)
# Define input tensor
input_tensor = torch.randn(32, 128) # Batch size of 32, 128 features
output = model(input_tensor)
print(output)
Code Examples
Check out the programmer.ie notebooks for the code used in this post and additional examples.