SVM Support Vector Machine an introduction
Summary
In this post I will implement a Support Vector Machine (SVM) in python. Then describe what it does how it does it and some applications of the instrument.
What Are Support Vector Machines (SVM)?
Support Vector Machines (SVM) are supervised learning algorithms used for classification and regression tasks. Their strength lies in handling both linear and non-linear problems effectively. By finding the optimal hyperplane that separates classes, SVMs maximize the margin between data points of different classes, making them highly effective in high-dimensional spaces.
Key Concepts
-
Hyperplane:
- A decision boundary that separates data into different classes.
- In a 2D space, it is a line; in 3D, it is a plane.
-
Support Vectors:
- Data points closest to the hyperplane. They are critical in defining the boundary.
-
Margin:
- The distance between the hyperplane and the nearest data points from either class (support vectors).
- SVM aims to maximize this margin to improve generalization.
-
Kernel Trick:
- Transforms data into higher dimensions to handle non-linear relationships.
- Common kernels: Linear, Polynomial, Radial Basis Function (RBF), and Sigmoid.
Why Use SVMs?
- Effective in High Dimensions: Handles datasets with many features, even when the number of dimensions exceeds the number of samples.
- Robust to Overfitting: Particularly effective when the dataset is sparse.
- Customizable: With kernels, SVMs adapt to various complex problems.
Implementing a SVM in Python
class SVM:
def __init__(self, learning_rate=0.001, lambda_param=0.01, n_iters=1000):
self.lr = learning_rate
self.lambda_param = lambda_param
self.n_iters = n_iters
self.w = None
self.b = None
def fit(self, X, y):
n_samples, n_features = X.shape
y_ = np.where(y <= 0, -1, 1)
# init weights
self.w = np.zeros(n_features)
self.b = 0
for _ in range(self.n_iters):
for idx, x_i in enumerate(X):
condition = y_[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
self.w -= self.lr * (2 * self.lambda_param * self.w)
else:
self.w -= self.lr * (
2 * self.lambda_param * self.w - np.dot(x_i, y_[idx])
)
self.b -= self.lr * y_[idx]
def predict(self, X):
approx = np.dot(X, self.w) - self.b
return np.sign(approx)
Code explanation
**1️⃣ Initialization (__init__ method)
learning_rate: The step size for updating the weights during optimization.lambda_param: The regularization parameter to prevent overfitting by penalizing large weights.n_iters: Number of iterations to run the training loop.wandb: Model parameters (weights and bias) initialized during training.
**2️⃣ Training the Model (fit method)
- Inputs:
X(feature matrix) andy(target labels, typically -1 or 1). y_: Convertsyinto a format compatible with the SVM loss function (ensures labels are either -1 or 1).- Initializes
w(weights) as a zero vector andb(bias) as 0.
The algorithm iterates through the data for n_iters:
- For each data point
x_i, it checks the condition:
\( y_i (\mathbf{w} \cdot \mathbf{x}_i - b) \geq 1 \)
This ensures the data point lies on or beyond the correct side of the margin. - If the condition is met: The weights are updated by penalizing only the regularization term.
- If the condition is not met: The weights and bias are updated to reduce the loss and correct the misclassified point.
**3️⃣ Making Predictions (predict method)
- Computes \( \text{sign}(\mathbf{w} \cdot \mathbf{x} - b) \) for each sample in
X. - Returns the class label (-1 or 1) based on whether the value is negative or positive.
Key Points:
- This implementation uses the Hinge Loss for classification and incorporates L2 regularization to improve generalization.
Using scikit-learn
Python’s scikit-learn library provides a user-friendly interface to implement SVMs efficiently.
Step 1: Create some sample data for testing
Here’s an example using a synthetic dataset for binary classification:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
# Generate synthetic dataset
X, y = make_classification(
n_samples=100, n_features=2, n_classes=2, n_clusters_per_class=1, random_state=42
)
# Visualize the data
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', edgecolors='k')
plt.title("Synthetic Dataset")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
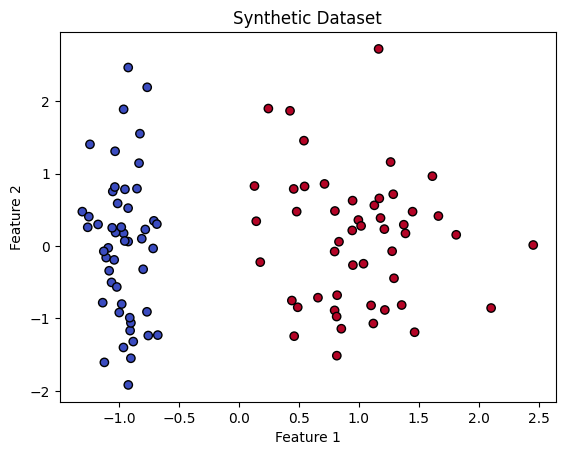
Step 2: Train an SVM Model
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train an SVM classifier with a linear kernel
model = SVC(kernel='linear', C=1.0) # 'C' is the regularization parameter
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred):.2f}")
Accuracy: 1.00
Step 3: Visualize the Decision Boundary
def plot_decision_boundary(X, y, model):
# Create a mesh grid
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
# Predict labels for the grid points
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot decision boundary
plt.contourf(xx, yy, Z, alpha=0.8, cmap='coolwarm')
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap='coolwarm')
plt.title("SVM Decision Boundary")
plt.show()
plot_decision_boundary(X, y, model)
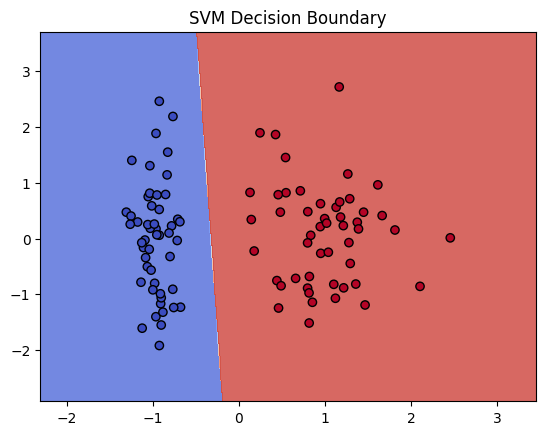
Step 4: Visualize the hyperplane and margins
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_blobs
# Generate a toy dataset
X, y = make_blobs(n_samples=50, centers=2, random_state=0)
# Create an SVM classifier
clf = SVC(kernel='linear')
clf.fit(X, y)
# Get the coefficients of the hyperplane
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-5, 5)
yy = a * xx - (clf.intercept_[0]) / w[1]
# Plot the data points
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)
# Plot the hyperplane
plt.plot(xx, yy, 'k-', label='hyperplane')
# Plot the margins
yy_down = a * xx + (1 - clf.intercept_[0]) / w[1]
yy_up = a * xx + (-1 - clf.intercept_[0]) / w[1]
plt.plot(xx, yy_down, 'k--', label='margins')
plt.plot(xx, yy_up, 'k--')
# Support vectors
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=80, facecolors='none', edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
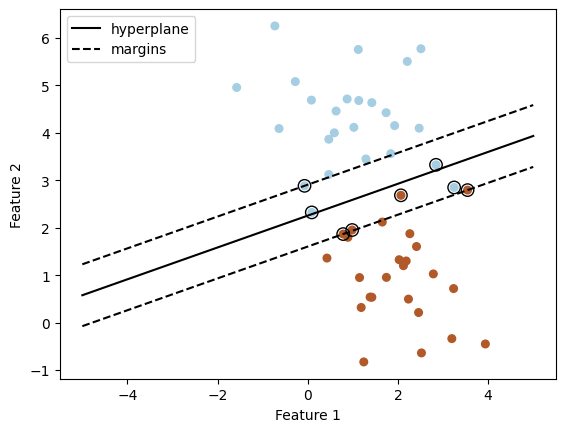
Working with Non-linear Data
For non-linear problems, we can use kernels like RBF:
# Train SVM with RBF kernel
model_rbf = SVC(kernel='rbf', C=1.0, gamma=0.5) # 'gamma' defines the influence of each point
model_rbf.fit(X_train, y_train)
# Visualize the decision boundary
plot_decision_boundary(X, y, model_rbf)
When to Use SVM?
- Small to Medium Datasets: SVMs work best when the dataset size is not excessively large.
- High Dimensionality: They excel when the number of features is large relative to samples.
- Clear Margin of Separation: Ideal for problems with a clear boundary between classes.
Advantages and Limitations
Advantages:
- Effective in high dimensions.
- Customizable through kernels.
- Works well with limited samples.
Limitations:
- Not ideal for very large datasets due to computational cost.
- Sensitive to parameter tuning (e.g., kernel type, regularization).
Extensions
- Multiclass Classification: Use
One-vs-OneorOne-vs-Reststrategies. - Regression: SVMs also work for regression tasks using
SVR. - Hyperparameter Tuning: Use Grid Search (
GridSearchCV) or Random Search (RandomizedSearchCV) to find the optimal parameters.
from sklearn.model_selection import GridSearchCV
# Define parameter grid
param_grid = {
'C': [0.1, 1, 10],
'gamma': [0.1, 0.5, 1],
'kernel': ['rbf', 'linear']
}
# Grid Search
grid = GridSearchCV(SVC(), param_grid, refit=True, cv=5)
grid.fit(X_train, y_train)
print(f"Best Parameters: {grid.best_params_}")
Best Parameters: {'C': 0.1, 'gamma': 0.1, 'kernel': 'rbf'}
Using an SVM with a LLM to classify text data
In this example we use an SVM to classify text data the tex data is first processed using a Large Language Model
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Load the pre-trained LLM model and tokenizer
model_name = "bert-base-uncased" # Example: BERT
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Sample dataset (replace with your actual data)
data = [
("This is a positive sentiment.", 1),
("I am very disappointed.", 0),
("Neutral opinion.", 2),
# ... more examples
]
# Preprocess the data
texts = [item[0] for item in data]
labels = [item[1] for item in data]
# Tokenize the text
encoded_inputs = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Get the LLM embeddings
with torch.no_grad():
outputs = model(**encoded_inputs)
embeddings = outputs.last_hidden_state[:, 0, :] # Extract the first token's embedding
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(embeddings.numpy(), labels, test_size=0.2, random_state=42)
# Train the SVM classifier
svm_model = SVC(kernel='linear') # You can experiment with different kernels
svm_model.fit(X_train, y_train)
# Make predictions
y_pred = svm_model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
Code Examples
Check out the svm notebooks for the code used in this post and additional examples.