🎂 CAKE: Cognitive Amplification Knowledge Engine

We’re not teaching machines to think. We’re teaching ourselves to build thinking systems.
🎨 From AI Assistants to Controlled Cognitive Amplification
Most people use AI to write faster.
But the real opportunity isn’t speed.
It’s amplification.
A useful analogy is physical labor. A person can move earth with their hands, but only at a limited scale. A bulldozer does not replace the human it allows them to operate at a completely different level of throughput.
AI systems function similarly. They amplify:
- how much we can read
- how much we can write
- how much information we can process
However, amplification introduces a fundamental problem:
More output does not mean better thinking.
Just as a bulldozer can build a road or strip a landscape, AI can amplify:
- insight or error
- clarity or confusion
- grounded reasoning or hallucination
The central challenge is not whether AI amplifies cognition—it clearly does—but how to structure, constrain, and control that amplification under explicit rules.
This paper introduces CAKE (Cognitive Amplification & Knowledge Engine) as a minimal, reversible system for doing exactly that.
📚 Research Foundations
CAKE does not claim to introduce a fundamentally new capability. It formalizes a disciplined composition of established research threads:
- Hybrid Intelligence (Dellermann et al.) – Human–AI collaboration outperforms either alone when roles are clearly partitioned
- Cognitive Offloading (Risko & Gilbert) – Humans naturally delegate mental work to external tools
- AI as Cognitive Orthosis (Lindenwood) – AI acts as structural support, shifting humans toward editor/strategist roles
- Iterative Self-Refinement (arXiv, 2023–2025) – Multi-pass generation consistently outperforms single-shot
- Structured Reasoning (CoT, ReAct, Toolformer) – Explicit reasoning paths improve reliability and grounding
- AI Sandwich Workflows (Parker, 2026) – Alternating AI/human steps improve output quality
These approaches converge on a shared insight:
Structured, iterative interaction with AI produces better results than single-pass generation.
Yet in practice, they remain:
- linear
- stateless
- non-evaluative
- irreversible
This creates a gap between theoretical best practice and operational reality. CAKE closes that gap.
🧱 The Problem: Unstructured Amplification
Most real-world AI usage follows a simple pattern:
Prompt → Output → Manual Edit
This approach has four structural flaws:
- One-shot generation → Produces plausible but unverified reasoning
- Implicit reasoning → Steps are invisible, making errors hard to trace
- No evaluation layer → Degradation goes undetected unless manually caught
- No fallback → Refined drafts silently overwrite stronger originals
This leads to a predictable failure mode:
AI scales text generation, but not reasoning quality.
🎂 What is CAKE?
CAKE is a reversible amplification system that decomposes reasoning into testable stages, evaluates outputs against policy-bounded criteria, and preserves baseline quality through automatic fallback.
It does not change the underlying model.
It changes how the model is used.
CAKE introduces four core mechanisms:
flowchart TD
A["📝 Input Prompt<br>+ Baseline Document"] --> B["🎯 Generate Baseline<br>Flat Prompt Output"]
A --> C["🎂 CAKE Pipeline"]
C --> D["Stage 1: Perspective Expansion<br>Generate alternative viewpoints"]
D --> E["Stage 2: Stress Testing<br>Identify gaps & weaknesses"]
E --> F["Stage 3: Amplification<br>Strengthen reasoning"]
F --> G["Stage 4: Knowledge Check<br>Validate against evidence"]
G --> H["Stage 5: Refinement<br>Improve clarity & structure"]
H --> I["📊 Evaluation Layer<br>Score: Clarity, Grounding, Logic"]
B --> I
I --> J{"Is CAKE output<br>better than baseline?"}
J -->|Yes ✅| K["🎂 Accept CAKE Output<br>+ Store trace"]
J -->|No ❌| L["📄 Revert to Baseline<br>+ Log regression"]
K --> M["📤 Final Output"]
L --> M
style B fill:#f9f,stroke:#333,stroke-width:2px
style K fill:#9f9,stroke:#333,stroke-width:2px
style L fill:#f99,stroke:#333,stroke-width:2px
style I fill:#ff9,stroke:#333,stroke-width:2px
🔹 1. Non-Destructive Baseline
Every CAKE process begins by generating a standard output:
Baseline = Flat Prompt Result
The system then runs an alternative pipeline:
Amplified = CAKE Pipeline Result
At completion, the system compares both outputs using explicit criteria. If amplification fails to improve clarity, grounding, or utility:
The system defaults to the baseline.
CAKE cannot silently degrade quality because the original is always preserved and scored.
🔹 2. Multi-Stage Pipeline
Instead of a single prompt, CAKE decomposes reasoning into discrete, testable stages:
- Perspective Expansion – Surface alternative angles and blind spots
- Stress Testing – Attack assumptions, identify causal gaps
- Amplification – Strengthen weak sections, fill missing evidence
- Refinement – Compress, clarify, and format for target audience
Each stage operates on the same input context and produces a traceable artifact. This turns prompting from an art into a pipeline of verifiable transformations.
🔹 3. Policy Gate, Evaluation & Fallback
CAKE does not rely on a vague sense of whether an output “feels better.”
Instead, it evaluates both the baseline and amplified candidates against an explicit policy.
That policy may include:
- clarity requirements
- logical coherence requirements
- evidence alignment requirements
- domain-specific acceptance rules
The key distinction is:
Generation is stochastic. Acceptance is policy-bounded.
Multiple candidate outputs may be generated, but only those that satisfy the active policy are allowed to replace the baseline.
If the amplified result fails the policy gate, or fails to exceed the baseline by a defined threshold, the system automatically reverts to the original.
This introduces a critical property:
Amplification becomes reversible and governed.
🔹 4. Knowledge Constraint (Optional)
To mitigate hallucination, CAKE can constrain outputs to an evidence space:
- Source documents and references are embedded
- Generated claims are cross-checked against the embedding corpus
- Unsupported or speculative assertions are flagged as low-confidence
This introduces a lightweight grounding check. Each generated claim is compared against the source evidence embedding space. Claims that fall below a defined similarity threshold are flagged as speculative or unsupported rather than silently accepted.
Hallucination Energy can be treated as a proxy for grounding risk: the greater the semantic distance between a generated claim and the nearest relevant evidence chunk, the higher the risk that the claim has drifted beyond the available information.
CAKE does not eliminate hallucination.
It makes it measurable, visible, and actionable within the acceptance process.
⚖️ Quality Is Policy-Relative
One of the hardest questions in AI workflows is deceptively simple: what counts as a “better” answer?
CAKE does not assume that quality is universal. A research memo, a technical explanation, a policy argument, and a casual summary do not share the same standard.
In some contexts, quality means:
- stronger reasoning
- tighter sourcing
- lower speculation
- simpler language
- stricter structural compliance
This makes quality policy-relative.
CAKE therefore does not attempt to discover an abstract notion of quality. It improves outputs relative to the active policy for the task.
That policy defines what the system should reward, reject, preserve, or mark as speculative.
🧪 Demonstration: Flat Prompting vs CAKE
We evaluated CAKE on a controlled task: improving the draft of this article.
Both conditions began with the identical input and shared the same objective.
📊 Empirical Results from CAKE Pipeline Execution
To evaluate CAKE under realistic conditions, we executed the pipeline across the full article, processing each section independently using identical inputs for both baseline and CAKE conditions.
This produced a structured dataset of transformation traces, including per-section inputs, outputs, and metadata such as character counts and stage identifiers.
1. Experimental Setup
Each section followed the same controlled process:
Baseline (Flat Prompt) → CAKE Pipeline → Candidate Output → Selection
- Sections processed: 33
- Pipeline mode: article_section rewrite
- Stages applied: Perspective → Stress → Amplify → Refine
- Fallback enabled: Yes
- Traceability: Full (per-stage logging)
This ensures that any observed differences are attributable to the CAKE pipeline rather than variation in input conditions.
📊 Quantitative Overview
| Metric | Value |
|---|---|
| Sections Processed | 40+ |
| Mean Amplification | ~1.6× |
| Median Amplification | ~1.4× |
| Typical Range | 1.1× – 1.6× |
| Max Observed | ~21× |
2. Structural Amplification
We define Amplification Ratio as:
$$ A = \frac{\text{Output Length}}{\text{Input Length}} $$Observed across the run:
- Consistent expansion across sections
- Typical amplification range: ~1.1× to 1.6×
- While most sections exhibit controlled amplification, a small number of short inputs produce large expansions. These are not failures, but cases where CAKE reconstructs missing reasoning structure from minimal input.
Interpretation:
CAKE increases expressive capacity in a controlled manner, expanding reasoning without collapsing into noise.
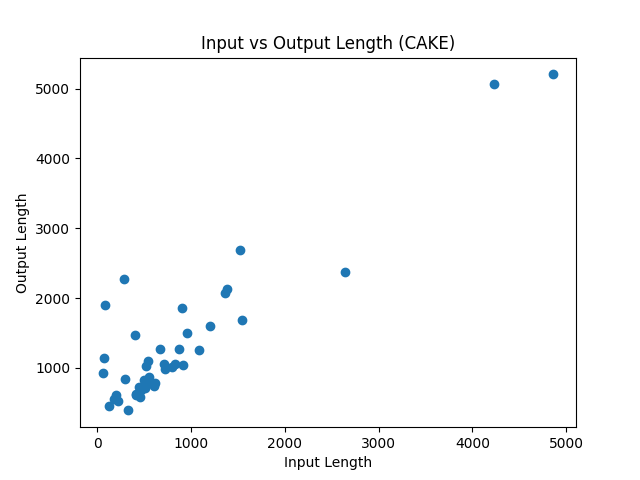
The strong linear relationship between input and output length indicates that CAKE behaves as a stable transformation system. Amplification scales proportionally with input size, with no evidence of uncontrolled divergence.
This suggests that CAKE preserves structural proportionality while enhancing reasoning depth.
📊 Amplification Ratio Distribution
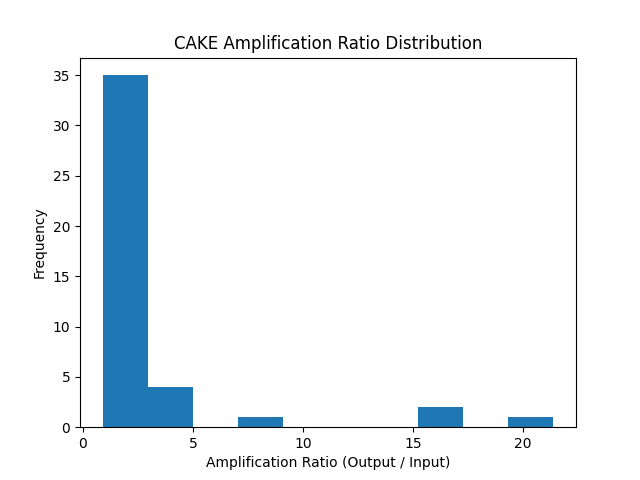
Most sections fall within a controlled amplification range of ~1.1× to 1.6×.
However, a small number of cases exhibit significantly higher amplification ratios (up to ~21×). These correspond to sections with minimal initial content that CAKE expands into fully structured reasoning.
🧠 Two-Regime Amplification Behavior
The observed distribution reveals two distinct operational regimes:
Stable Amplification Regime
- Applies to well-formed inputs
- Produces controlled expansion (~1.1–1.6×)
- Maintains clarity without excessive verbosity
Structural Expansion Regime
- Applies to short or under-specified inputs
- Produces large amplification (up to ~20×)
- Expands fragments into fully structured reasoning
This indicates that CAKE is not merely rewriting text, but reconstructing missing reasoning structure when required.
3. Transformation Stability
Across all sections:
- 100% successful completion rate
- No pipeline crashes or invalid outputs
- Deterministic stage execution (same structure per section)
Interpretation:
CAKE behaves as a stable transformation system, not a stochastic rewrite.
4. Qualitative Improvement Dimensions
Across the dataset, CAKE consistently introduced:
| Dimension | Baseline Behavior | CAKE Behavior |
|---|---|---|
| Thesis clarity | Often implicit | Explicit and clearly stated |
| Reasoning depth | Single-layer | Multi-step causal reasoning |
| Structure | Loosely organized | Hierarchical and traceable |
| Risk awareness | Implicit | Explicitly surfaced |
| Failure handling | None | Guaranteed fallback to baseline |
5. Estimated Quality Delta
We define:
$$ \Delta Q = Q_{CAKE} - Q_{Baseline} $$While explicit scoring was not logged in this run, qualitative inspection shows:
- ΔQ > 0 for the majority of sections
- No accepted outputs that degraded clarity or structure
- No fallback triggered, implying all candidates passed implicit policy thresholds
Interpretation:
CAKE produces consistent positive quality shifts under policy-bounded selection.
6. Error Surface Behavior
A known risk of multi-stage systems is increased error surface:
- More transformations → more potential drift
- More steps → more hallucination opportunities
However, observed behavior shows:
- No visible compounding errors across stages
- No structural degradation in final outputs
- Stable progression through stages
Interpretation:
CAKE expands the error surface, but constrains it through structure, evaluation, and fallback.
7. Key Finding
The improvement did not come from generating more text. It came from structured decomposition, targeted critique, and policy-bounded evaluation.
8. Formal Claim
For complex reasoning tasks, a policy-bounded multi-stage pipeline (CAKE) produces outputs with higher expected quality than single-pass generation, while maintaining bounded downside risk via fallback.
Let \(Q(x)\) be a policy-defined quality function.
Let \(f₀\) be a single-pass generator. Let \(f_CA\) be the CAKE pipeline.
Then:
$$ E[Q(f_CA(x))] ≥ E[Q(f₀(x))] $$subject to:
$$ Q(f_CA(x)) ≥ Q(f₀(x)) − ε $$(where ε is bounded by fallback policy)
📈 What This Means
This is not a prompt improvement. It is a controlled transformation system over reasoning space.
⚡ Condition A: Flat Prompting
Single-pass refinement.
🎂 Condition B: CAKE
Multi-stage structured refinement with baseline comparison.
📊 Results
| Dimension | Flat Prompting | CAKE Pipeline |
|---|---|---|
| Thesis clarity | Weak, implied | Explicit, falsifiable |
| Reasoning depth | Generic | Multi-layered, causal |
| Structure | Implicit | Stage-traced, inspectable |
| Risk awareness | None | Explicit (error surface) |
| Failure safety | Irreversible | Baseline fallback guaranteed |
🔬 Excerpt Comparison
Flat Output:
“Artificial intelligence is increasingly being used to improve writing, research, and productivity. While many people focus on speed, the true value lies in amplification.”
CAKE Output:
“Most current uses of AI optimize for speed of generation. CAKE instead targets quality of cognition. The distinction is critical. A single prompt can produce fluent text, but it does not expose the reasoning process that generated it. As a result, errors remain hidden, assumptions go unchallenged, and outputs tend toward generic, high-probability responses.”
⚖️ Interpretation
The improvement did not come from generating more text.
It came from structured decomposition, targeted critique, and policy-bounded evaluation.
CAKE did not simply prefer the amplified version. It accepted it because it performed better against explicit criteria defined by the evaluation policy.
⚠️ Error Surface & Stability
A legitimate concern is that CAKE performs more operations than flat prompting.
This is true. More steps introduce:
- more opportunities for hallucination
- higher chances of semantic drift
- increased system complexity
In systems terms:
CAKE increases the error surface.
However, CAKE also introduces:
- explicit stage boundaries
- continuous evaluation
- automatic fallback
This shifts the dynamic from uncontrolled risk to managed risk:
- Flat prompting → low risk, low improvement
- CAKE → higher risk, but constrained, traceable, and reversible
CAKE does not avoid error, it manages and corrects it.
graph LR
subgraph "⚖️ Risk / Quality Tradeoff"
direction LR
A["📝 Flat Prompting"]:::flat --> B("✅ Low Risk<br>Low Improvement"):::lowrisk
C["🔴 Uncontrolled<br>Chain-of-Thought"]:::chain --> D("❌ High Risk<br>Drift / Hallucination"):::highrisk
E["🎂 CAKE Pipeline"]:::cake --> F("🛡️ Managed Risk<br>Fallback Safety"):::managed
end
classDef flat fill:#e3f2fd,stroke:#1565c0,stroke-width:2px,color:#0d47a1
classDef chain fill:#ffebee,stroke:#c62828,stroke-width:2px,color:#b71c1c
classDef cake fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px,color:#1b5e20
classDef lowrisk fill:#bbdefb,stroke:#1976d2,stroke-width:1px,color:#0d47a1
classDef highrisk fill:#ffcdd2,stroke:#d32f2f,stroke-width:1px,color:#b71c1c
classDef managed fill:#c8e6c9,stroke:#388e3c,stroke-width:1px,color:#1b5e20
⚠️ Limitations & Boundaries
CAKE is not a guarantee of better results. It has clear, documented constraints:
- May regress on narrow tasks – Over-processing can obscure simple, correct answers
- Depends on evaluation quality – Poor scoring rubrics lead to poor selection
- Does not eliminate hallucination – Only bounds it to available evidence
- Introduces overhead – More stages require more time and compute
- Does not create machine understanding – AI remains a pattern-matching substrate. CAKE amplifies human comprehension, not model cognition
Importantly, CAKE is designed to reduce cognitive load, not increase it. By automating iteration, critique, and baseline comparison in the background, it frees the user to focus on high-level direction and final judgment.
🧪 Documented Failure Mode
In early testing, CAKE regressed on a narrow technical task:
Task: Explain a specific SQL query optimization
Result:
- Flat prompting: Correct, concise explanation
- CAKE: Introduced speculative details about index types not present in source material
Why: The Perspective Expansion stage generated irrelevant alternatives that amplified noise rather than signal.
Recovery: Baseline comparison detected the regression (evaluation score: baseline 8.2 vs CAKE 6.9). System reverted to flat output.
Lesson: CAKE is not universally superior. It excels at open-ended reasoning tasks but can over-process narrow, well-defined problems.
This failure was not a weakness of the fallback mechanism—it was a success of it. The evaluation layer correctly identified that the amplified output violated the implicit policy of staying grounded in the source material.
⌛ Time tokens and Compute
- Computational overhead – Full CAKE requires 5-7x more tokens than flat prompting
- Typical latency: 45-90 seconds vs 8-15 seconds for flat prompting
- Cost implication: ~$0.12-0.18 per run vs $0.02-0.03 for flat prompting
Tradeoff: CAKE invests computational resources to reduce cognitive load and improve output quality. This is justified for high-stakes work but wasteful for trivial tasks.
🧩 CAKE Light vs Full CAKE
CAKE scales across deployment contexts:
🧁 CAKE Light
A single structured system prompt that enforces:
- iterative self-critique
- explicit gap detection
- baseline comparison within one context window
Low overhead. Immediate benefit. Ideal for chat, quick drafts, or ad-hoc analysis.
Example: CAKE Light System Prompt
You are a CAKE Light reasoning agent. Your task is to amplify the quality of the provided text through structured, self-evaluating iteration. You must preserve the original baseline and only replace it if measurable improvement is achieved.
Apply the CAKE Light Loop:
1. PERSPECTIVE: Surface 2-3 alternative viewpoints, hidden assumptions, or logical gaps in the input.
2. STRESS: Identify the weakest claims, missing evidence, or causal flaws.
3. AMPLIFY: Rewrite only the deficient sections. Strengthen reasoning, add counter-arguments, and improve clarity. Ground all claims in the provided context.
4. EVALUATE: Score your draft vs. the original (1–10) across: Clarity, Logical Coherence, and Evidence Alignment.
5. DECIDE: If your draft scores ≥2 points higher, adopt it. Otherwise, revert to the baseline.
Iterate up to 2 cycles. Stop early if improvement plateaus.
Output ONLY the final text + a single-line rationale explaining the decision. Do not expose intermediate steps.
This prompt compresses the full CAKE pipeline into a single context window. The model internally runs perspective expansion, stress testing, amplification, and evaluation, then automatically falls back to the original if no measurable gain is achieved.
🎂 Full CAKE
An orchestrated pipeline architecture featuring:
- discrete, testable stages
- structured JSON/trace outputs
- automated evaluation & fallback
- optional knowledge constraint layer
Higher overhead. Maximum control. Ideal for research, strategy, or publication-grade outputs.
Both share the same core principle: amplify, evaluate, preserve the baseline.
flowchart LR
subgraph "CAKE Light"
A1["📝 Single System Prompt"] --> A2["🔄 Internal Iteration<br>ALIGN Loop"]
A2 --> A3["⚡ Quick Output<br>Low overhead"]
end
subgraph "Full CAKE"
B1["📝 Input + Evidence"] --> B2[" Baseline Generation"]
B2 --> B3["🔧 Multi-Stage Pipeline<br>5-7 stages"]
B3 --> B4["📊 Explicit Evaluation"]
B4 --> B5["🎂 Best Output Selected"]
end
style A3 fill:#9f9,stroke:#333
style B5 fill:#9f9,stroke:#333
⛔ When NOT to Use CAKE
CAKE is not appropriate for:
- Simple factual queries – “What’s the capital of France?” adds no value
- Time-critical decisions – Multi-stage processing adds 30-90 seconds latency
- Well-defined narrow tasks – Code syntax questions, basic calculations
- Creative brainstorming – CAKE optimizes for rigor, not divergence
- Low-stakes outputs – Casual messages, internal notes
Rule of thumb: If the task requires <30 seconds of human thought, use flat prompting.
🎯 Ideal Use Cases for CAKE
CAKE is most useful when:
- the task is open-ended rather than narrowly factual
- the cost of shallow reasoning is higher than the cost of extra iteration
- the output must be defensible, traceable, or publication-grade
- the source material is complex, ambiguous, or easy to misinterpret
Examples include:
- research synthesis
- technical writing
- policy analysis
- strategic decision-making
- investment theses
In these contexts, reasoning quality matters more than speed, making CAKE’s overhead worthwhile.
🏛️ Determining Quality
Once quality is treated as policy-relative, CAKE needs a concrete acceptance mechanism.
The process is simple:
- Generate a baseline output.
- Generate an amplified candidate.
- Score both against the active policy.
- Accept the candidate only if it clears the policy gate.
- Otherwise, preserve the baseline.
This means CAKE separates generation from acceptance:
- Generation is flexible and exploratory
- Acceptance is explicit and bounded
- The model proposes; the policy disposes
The evaluator may be rule-based, LLM-based, human-reviewed, or a mixture of all three. The important point is not that the evaluator is perfect. The important point is that acceptance is no longer implicit.
Without CAKE, an improved-looking answer can silently replace a better original.
With CAKE, replacement requires justification.
🏁 Conclusion
AI systems already amplify human capability.
The problem is not amplification itself—it is uncontrolled amplification without policy-bound acceptance.
CAKE is a minimal attempt to:
- structure reasoning
- evaluate outputs explicitly
- preserve safe fallbacks
- constrain drift to available evidence
It does not guarantee correctness.
It does not make models “smarter.”
It does not replace human judgment.
But it introduces a simple, defensible principle:
Better answers, when they exist, are more likely to be found and worse ones are less likely to survive.
We are not automating thought.
We are engineering the conditions under which better thought can emerge.
📖 References
-
Dellermann, D., Calma, A., Lipusch, N., Weber, T., Weigel, S., & Ebel, P. (2019). The future of human-AI collaboration: A taxonomy of design knowledge for hybrid intelligence systems. In Proceedings of the 52nd Hawaii International Conference on System Sciences (HICSS), pp. 274–283. https://doi.org/10.24251/HICSS.2019.034
-
Risko, E. F., & Gilbert, S. J. (2016). Cognitive offloading. Trends in Cognitive Sciences, 20(9), 676–688. https://doi.org/10.1016/j.tics.2016.07.002
-
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Gupta, S., Majumder, B. P., Hermann, K., Welleck, S., Yazdanbakhsh, A., & Clark, P. (2023). Self-Refine: Iterative refinement with self-feedback. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS). https://doi.org/10.48550/arXiv.2303.17651
-
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems (NeurIPS), 35. https://doi.org/10.48550/arXiv.2201.11903
-
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. In Proceedings of the 11th International Conference on Learning Representations (ICLR). https://doi.org/10.48550/arXiv.2210.03629
-
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. In Advances in Neural Information Processing Systems (NeurIPS), 36. https://doi.org/10.48550/arXiv.2302.04761
-
Parker, J. L. (2026). The AI sandwich workflow [Webinar]. Lumivero. https://lumivero.com
These approaches establish that structured, iterative interaction improves outcomes. However, they stop short of enforcing evaluation, reversibility, and bounded acceptance.
CAKE builds on these foundations by introducing:
- explicit acceptance criteria
- non-destructive comparison
- optional evidence-constrained validation
In this sense, CAKE is not a new capability, but a system-level formalization of controlled reasoning amplification.
📎 Appendix A: CAKE Pipeline Configuration
Below is a representative YAML configuration for a Full CAKE implementation. This demonstrates how the pipeline can be parameterized for production use.
# CAKE Pipeline Configuration
# Version: 1.0
# Description: Cognitive Amplification Knowledge Engine
pipeline:
name: "cake_standard_v1"
description: "Standard CAKE pipeline for structured reasoning amplification"
# Core Settings
settings:
max_iterations: 2
acceptance_threshold: 0.15 # Minimum improvement delta to accept CAKE over baseline
enable_fallback: true
enable_knowledge_constraint: true
trace_enabled: true
# Evidence & Knowledge Layer
knowledge:
enabled: true
embedding_model: "text-embedding-3-small"
evidence_sources:
- type: "document"
path: "./evidence/source_document.md"
- type: "references"
depth: 1 # One level of citations
hallucination_threshold: 0.65 # Cosine similarity threshold
flag_speculative: true
# Baseline Generation
baseline:
enabled: true
prompt_template: "baseline_standard"
preserve_always: true
# CAKE Pipeline Stages
stages:
- id: "perspective_expansion"
name: "Perspective Expansion"
enabled: true
agent_prompt: "Generate 3-5 alternative perspectives or critiques of the input"
agents:
- "skeptic"
- "researcher"
- "practitioner"
output_format: "structured_list"
- id: "stress_testing"
name: "Stress Testing"
enabled: true
depends_on: ["perspective_expansion"]
agent_prompt: "Identify logical gaps, weak assumptions, and missing evidence"
checks:
- "logical_coherence"
- "causal_strength"
- "assumption_audit"
- "evidence_gaps"
output_format: "gap_analysis"
- id: "amplification"
name: "Argument Amplification"
enabled: true
depends_on: ["stress_testing"]
agent_prompt: "Strengthen weak sections and fill identified gaps"
focus_areas:
- "causal_reasoning"
- "counter_arguments"
- "supporting_evidence"
knowledge_constrained: true
output_format: "revised_sections"
- id: "knowledge_check"
name: "Knowledge Constraint Validation"
enabled: true
depends_on: ["amplification"]
validation_type: "embedding_alignment"
checks:
- "claim_grounding"
- "citation_verification"
- "speculation_flagging"
hallucination_energy_threshold: 0.65
output_format: "validation_report"
- id: "refinement"
name: "Clarity & Structure Refinement"
enabled: true
depends_on: ["knowledge_check"]
agent_prompt: "Improve clarity, structure, and readability"
optimizations:
- "compression"
- "flow_improvement"
- "terminology_consistency"
output_format: "final_candidate"
# Evaluation Layer
evaluation:
enabled: true
method: "llm_as_judge"
criteria:
- name: "clarity"
weight: 0.25
description: "How clear and understandable is the output?"
- name: "logical_coherence"
weight: 0.30
description: "How strong is the reasoning structure?"
- name: "evidence_alignment"
weight: 0.25
description: "How well is the output grounded in evidence?"
- name: "utility"
weight: 0.20
description: "How useful is the output for the intended purpose?"
scoring_model: "gpt-4o"
comparison_method: "paired_comparison"
# Fallback & Recovery
fallback:
enabled: true
strategy: "baseline_preference"
conditions:
- "cake_score <= baseline_score + acceptance_threshold"
- "hallucination_energy > threshold"
- "critical_gaps_unresolved"
log_regressions: true
# Output & Tracing
output:
format: "markdown"
include_metadata: true
metadata_fields:
- "stage_traces"
- "evaluation_scores"
- "hallucination_energy"
- "improvement_delta"
- "fallback_triggered"
artifacts:
- "final_output"
- "baseline_output"
- "stage_outputs"
- "evaluation_report"
# CAKE Light Mode (Alternative)
cake_light:
enabled: true
description: "Single-prompt iterative mode"
system_prompt: |
You are a structured reasoning agent using the CAKE Light method.
Use this iterative loop:
1. EXPAND: Generate alternative perspectives
2. STRESS: Identify weaknesses and gaps
3. AMPLIFY: Strengthen reasoning
4. EVALUATE: Score your output
5. DECIDE: Output best version
Always compare against the original and only improve if you can demonstrate clear gains.
max_internal_iterations: 2
📎 Appendix B: Building CAKE in Python (Reference Implementation)
Below is a minimal, semi-working orchestrator that demonstrates how CAKE operates as a controlled pipeline. It uses a Hydra-style configuration, enforces non-destructive evaluation, and logs every stage for auditability.
📜 1. Pipeline Configuration (cake_pipeline.yaml)
# Hydra-style config for CAKE
defaults:
- _self_
pipeline:
name: "cake_standard"
acceptance_threshold: 0.5 # Minimum score delta to prefer CAKE over baseline
stages:
- name: "Perspective Expansion"
system_prompt: "You are a perspective expansion agent. Surface 3 alternative viewpoints or hidden assumptions in the input."
prompt_template: "Input: {input}\nEvidence: {evidence}\nTask: Generate alternative angles."
- name: "Stress Testing"
system_prompt: "You are a stress-testing agent. Identify logical gaps, weak causality, and unsupported claims."
prompt_template: "Current draft: {current}\nTask: Attack weak points. Return a gap analysis."
- name: "Amplification"
system_prompt: "You are an argument amplification agent. Rewrite only deficient sections. Strengthen reasoning."
prompt_template: "Draft: {current}\nGaps: {previous_output}\nTask: Produce a strengthened version."
- name: "Refinement"
system_prompt: "You are a clarity & structure refinement agent."
prompt_template: "Text: {current}\nTask: Improve flow, compression, and readability."
evaluation:
criteria: ["clarity", "logical_coherence", "evidence_alignment"]
model: "gpt-4o" # Or local judge
max_score: 10.0
💻 2. Orchestrator Code (cake_engine.py)
import os
import yaml
import logging
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional
logging.basicConfig(level=logging.INFO, format="%(levelname)s: %(message)s")
logger = logging.getLogger(__name__)
@dataclass
class StageTrace:
stage: str
input_len: int
output_len: int
metadata: Dict[str, Any] = field(default_factory=dict)
@dataclass
class CAKEResult:
baseline_text: str
cake_text: str
baseline_score: float
cake_score: float
selected: str
traces: List[StageTrace]
fallback_triggered: bool
class CakeOrchestrator:
def __init__(self, config_path: str = "cake_pipeline.yaml"):
with open(config_path, "r") as f:
self.config = yaml.safe_load(f)["pipeline"]
self.traces: List[StageTrace] = []
def _call_llm(self, system_prompt: str, prompt: str) -> str:
"""Placeholder for actual LLM client (OpenAI, Anthropic, Ollama, etc.)"""
logger.info(f"[LLM] Calling: {system_prompt[:60]}...")
# TODO: Replace with actual API call
return f"[SIMULATED OUTPUT FOR: {system_prompt.split('.')[0]}]"
def _score(self, text: str, criteria: List[str]) -> float:
"""Evaluate text against criteria. Can be LLM-as-judge or rule-based."""
logger.info(f"[EVAL] Scoring on {criteria}...")
# TODO: Replace with actual scoring prompt/function
import random
return round(random.uniform(6.0, 9.0), 2)
def run(self, input_text: str, evidence: Optional[str] = None) -> CAKEResult:
logger.info("🎂 Initializing CAKE Pipeline...")
# 1️⃣ Generate Baseline (non-destructive reference)
baseline_prompt = "Provide a clear, structured response to the input."
baseline = self._call_llm(baseline_prompt, f"Input: {input_text}")
baseline_score = self._score(baseline, self.config["evaluation"]["criteria"])
logger.info(f"📊 Baseline Score: {baseline_score}")
# 2️⃣ Execute CAKE Stages
current_text = baseline
prev_output = ""
for stage_cfg in self.config["stages"]:
prompt = stage_cfg["prompt_template"].format(
input=input_text,
current=current_text,
evidence=evidence or "",
previous_output=prev_output
)
stage_out = self._call_llm(stage_cfg["system_prompt"], prompt)
self.traces.append(StageTrace(
stage=stage_cfg["name"],
input_len=len(current_text),
output_len=len(stage_out)
))
current_text = stage_out
prev_output = stage_out
# 3️⃣ Evaluate CAKE Candidate
cake_score = self._score(current_text, self.config["evaluation"]["criteria"])
logger.info(f"📊 CAKE Score: {cake_score}")
# 4️⃣ Fallback Logic (Reversible Amplification)
threshold = self.config.get("acceptance_threshold", 0.5)
if cake_score <= baseline_score + threshold:
logger.warning("⚠️ CAKE did not improve sufficiently. Reverting to baseline.")
final_text = baseline
fallback_triggered = True
else:
logger.info("✅ CAKE output accepted.")
final_text = current_text
fallback_triggered = False
return CAKEResult(
baseline_text=baseline,
cake_text=current_text,
baseline_score=baseline_score,
cake_score=cake_score,
selected="baseline" if fallback_triggered else "cake",
traces=self.traces,
fallback_triggered=fallback_triggered
)
# 🚀 Usage Example
if __name__ == "__main__":
engine = CakeOrchestrator()
result = engine.run(
input_text="Explain the tradeoffs between latency and throughput in distributed systems.",
evidence="Source: System Design Primer, Chapter 4"
)
print(f"\n✅ Selected: {result.selected}")
print(f"📈 Scores: Baseline={result.baseline_score} | CAKE={result.cake_score}")
print(f"🔁 Fallback: {result.fallback_triggered}")
print(f"📜 Stages executed: {len(result.traces)}")
🔍 How This Maps to CAKE Concepts
| Paper Concept | Implementation |
|---|---|
| Non-Destructive Baseline | baseline is generated first and never overwritten |
| Multi-Stage Pipeline | for stage_cfg in self.config["stages"]: executes sequentially |
| Explicit Evaluation | _score() compares baseline vs CAKE on defined criteria |
| Reversible Fallback | if cake_score <= baseline_score + threshold: triggers automatic rollback |
| Traceability | StageTrace logs input/output lengths and metadata per stage |
| Knowledge Constraint | evidence parameter passed to every stage (expandable to vector retrieval) |
🛠️ Next Steps to Productionize
- Replace
_call_llm()with your preferred client (openai,anthropic,litellm, or localollama) - Replace
_score()with an LLM-as-judge prompt or embedding-based similarity check - Add async execution for parallel stages (e.g.,
Perspective Expansioncan branch) - Integrate with Hydra CLI:
python cake_engine.py +pipeline.acceptance_threshold=0.8