Detecting AI-Generated Text: Challenges and Solutions
Summary
Artificial Intelligence (AI) has revolutionized the way we generate and consume text. From chatbots crafting customer responses to AI-authored articles, artificial intelligence is reshaping how we create and consume content. As AI-generated text becomes indistinguishable from human writing, distinguishing between the two has never been more critical. Here are some of the reasons it is important to be able to verify the source of information:
- Preventing plagiarism
- Maintaining academic integrity
- Ensuring transparency in content creation
- If AI models are repeatedly trained on AI-generated text, their quality may degrade over time.
In this blog post, we’ll explore the current most effective methods for detecting AI-generated text.
- AI model-based detection (e.g., RoBERTa)
- Perplexity & perturbation-based detection
- Sparse (SAEs) + XGBoost
We will also explore AI watermarking. This is where AI generated text has hidden markers to identify as AI.
Comparing Human and AI generated text
Let’s start with an example. This is some obvious AI vs human sentences.
10 Examples of AI-Generated vs. Human written sentences
AI-Generated Sentences (Overly Formal, Repetitive, Fact-Heavy, or Lacks Personality)
- “In the ever-evolving landscape of artificial intelligence, language models continue to demonstrate unprecedented capabilities in generating human-like text.”
- “The significance of sustainable energy solutions cannot be overstated in the modern era of climate change and environmental awareness.”
- “The Renaissance was a pivotal period in human history, characterized by remarkable advancements in art, science, and philosophy.”
- “Machine learning algorithms leverage vast datasets to optimize predictive performance in a variety of real-world applications.”
- “Throughout history, civilizations have relied on innovation to drive progress and enhance societal development.”
- “The impact of artificial intelligence on the global workforce is a topic of considerable debate among experts in the field.”
- “While natural language processing has significantly improved over the past decade, challenges in context retention and sentiment analysis remain.”
- “Technological advancements have revolutionized the way humans interact with digital ecosystems, fostering unprecedented levels of connectivity.”
- “The intricate relationship between data privacy and cybersecurity continues to shape global policies in the digital age.”
- “Future developments in artificial intelligence are expected to further blur the distinction between human and machine-generated content.”
Common Traits in AI-Generated Sentences:
- Overly formal and structured.
- Often too polished and generic.
- Repeats trendy phrases (e.g., “unprecedented capabilities”).
- Lacks personal insight, humor, or informal quirks.
Human-Written Sentences (Casual, Imperfect, Personal, or Context-Rich)
- “Honestly, I had no idea AI could write this well until I saw ChatGPT in action.”
- “I still remember that summer when we stayed up all night talking—somehow, those moments stick with you forever.”
- “I tried making sourdough bread last weekend, and let’s just say it was more of a rock than a loaf.”
- “Look, I know AI is cool and all, but I still don’t trust a machine to write my wedding vows.”
- “You ever get that weird feeling that you left the stove on, even though you know you didn’t?”
- “The coffee at that new place on 5th Street is honestly overrated—too bitter and way overpriced.”
- “I can’t explain why, but I really love the sound of rain hitting the roof at night.”
- “We spent the whole day hiking, only to realize we took the wrong trail back—thankfully, we had snacks!”
- “I swear, my cat understands English but just chooses to ignore me unless I say ‘treats.’”
- “Grandma always had the best stories about growing up in the countryside, and I wish I’d written them down.”
Common Traits in Human-Written Sentences:
- More casual and conversational.
- Uses contractions and informal phrasing.
- Includes personal experiences, emotions, or humor.
- Not perfectly structured (may have sentence fragments, run-ons, or slang).
AI Traits: Overly formal language arises because models are trained on large corpora of formal texts (e.g., academic papers, news articles). Human Traits: Informality stems from unique personal experiences, emotions, and context-specific communication.
However there are different types of Human writing
- Blogs style informal would be markedly different from AI
- Papers style formal would be closer to AI
- Books style informal would be close Human
- Technical books style formal would be close AI
Now that we’ve seen the differences, let’s explore how we can detect AI-generated text programmatically.
Method 1: AI Model-Based Detection (RoBERTa)
This is an older model for detecting AI generated text. We need to start here so we can see the challenges and understand what we need to do.
import sqlite3
from typing import List, Tuple
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
import torch
# Set device for model
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
print(f"Using device: {DEVICE}")
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("roberta-base-openai-detector")
model = AutoModelForSequenceClassification.from_pretrained("roberta-base-openai-detector")
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0 if DEVICE == "cuda:0" else -1)
# Initialize SQLite database
DB_NAME = "classification_results.db"
def initialize_database():
"""
Initializes the SQLite database and creates the classifications table if it doesn't exist.
"""
conn = sqlite3.connect(DB_NAME)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS classifications (
id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
line_text TEXT,
label TEXT,
confidence REAL
)
""")
conn.commit()
conn.close()
def classify_text(sentences: List[str]) -> List[Tuple[str, float]]:
"""
Classifies a list of sentences as 'Human' or 'AI' with confidence scores.
:param sentences: List of text inputs to classify.
:return: List of tuples containing the predicted label ('Human' or 'AI') and confidence score.
"""
results = pipe(sentences)
return [("Human" if res["label"] == "Real" else "AI", res["score"]) for res in results]
def classify_file(filename: str) -> List[Tuple[str, float]]:
"""
Reads a file line by line, classifies each line as 'Human' or 'AI', prints the results,
and stores them in an SQLite database.
:param filename: Name of the text file to classify.
:return: List of tuples containing classification results.
"""
results = []
with open(filename, "r", encoding="utf-8") as file:
lines = [line.strip() for line in file if line.strip()] # Remove empty lines
if not lines:
print(f"Warning: {filename} is empty or contains only whitespace.")
return results
classifications = classify_text(lines)
# Store results in SQLite
save_to_database(filename, lines, classifications)
# Print results
for line, classification in zip(lines, classifications):
print(f"{classification} : {line}")
results.append(classification)
return results
def save_to_database(filename: str, lines: List[str], classifications: List[Tuple[str, float]]):
"""
Saves classification results to an SQLite database.
:param filename: Name of the source file.
:param lines: List of text lines from the file.
:param classifications: List of classification results (label, confidence).
"""
conn = sqlite3.connect(DB_NAME)
cursor = conn.cursor()
data = [(filename, line, label, confidence) for line, (label, confidence) in zip(lines, classifications)]
cursor.executemany("INSERT INTO classifications (filename, line_text, label, confidence) VALUES (?, ?, ?, ?)", data)
conn.commit()
conn.close()
print(f"Results from {filename} saved to database.")
# Initialize database
initialize_database()
# Run classification and store results
classify_file("ai.txt")
classify_file("human.txt")
Results: Astonishingly bad
| Filename | Text | Score | Confidence | Label |
|---|---|---|---|---|
| ai.txt | “In the ever-evolving landscape of artificial inte… | 0.30 | 53.91% | Human-written |
| ai.txt | “The significance of sustainable energy solutions … | 0.27 | 55.08% | Human-written |
| ai.txt | “The Renaissance was a pivotal period in human his… | 0.76 | 64.04% | AI-generated |
| ai.txt | “Machine learning algorithms leverage vast dataset… | 0.05 | 63.59% | Human-written |
| ai.txt | “Throughout history, civilizations have relied on … | 0.40 | 50.02% | AI-generated |
| ai.txt | “The impact of artificial intelligence on the glob… | 0.48 | 53.23% | AI-generated |
| ai.txt | “While natural language processing has significant… | 0.03 | 64.61% | Human-written |
| ai.txt | “Technological advancements have revolutionized th… | 0.75 | 63.61% | AI-generated |
| ai.txt | “The intricate relationship between data privacy a… | 0.11 | 61.34% | Human-written |
| ai.txt | “Future developments in artificial intelligence ar… | 0.47 | 52.81% | AI-generated |
| human.txt | Honestly, I had no idea AI could write this well u… | 0.14 | 60.40% | Human-written |
| human.txt | I still remember that summer when we stayed up all… | 0.51 | 54.49% | AI-generated |
| human.txt | I tried making sourdough bread last weekend, and l… | -0.09 | 68.94% | Human-written |
| human.txt | Look, I know AI is cool and all, but I still don’t… | -0.06 | 67.63% | Human-written |
| human.txt | You ever get that weird feeling that you left the … | 0.16 | 59.63% | Human-written |
| human.txt | The coffee at that new place on 5th Street is hone… | 0.19 | 58.47% | Human-written |
| human.txt | I can’t explain why, but I really love the sound o… | 0.17 | 58.91% | Human-written |
| human.txt | We spent the whole day hiking, only to realize we … | 0.08 | 62.58% | Human-written |
| human.txt | I swear, my cat understands English but just choos… | -1.09 | 93.17% | Human-written |
| human.txt | Grandma always had the best stories about growing … | -0.75 | 87.52% | Human-written |
As we can see, the results are poor. The RoBERTa model was trained on GPT-2, but we are testing against GPT-4+. The model frequently misclassified AI text as human. The point I am making here is that the older models will find it difficult to detect newer models. We are working against a moving target.
Method 2: Perplexity & Perturbation-Based Detection
Perplexity measures how well a model predicts a given text. In simple terms:
Low perplexity: The text is predictable (common in AI-generated text).
High perplexity: The text is unexpected (common in human writing).
Example: GPT Perplexity on Different Texts
| Text Sample | GPT Perplexity Score | Why? |
|---|---|---|
| “The sun rises in the east.” | 2 (Low) | Very common phrase, easy for AI to predict. |
| “Neural networks revolutionized quantum linguistics.” | 5 (Medium) | Less common but still logical. |
| “Shakespeare’s sonnets unravel cosmic anomalies in Mars dust storms.” | 15.8 (High) | Rare, unexpected combination of words. |
AI-generated text tends to have lower perplexity than human text because it’s trained to produce highly fluent, predictable sentences.
Why AI Detection Needs More Than Just Perplexity
While perplexity is a good first step, it’s not enough for AI detection. Some human-written text also has low perplexity (e.g., simple sentences), and AI generated text can mimic complex writing styles.
Solution? We introduce perturbation.
Perturbation
Perturbation is a technique that slightly modifies a text (e.g., inserting words, shuffling sentences, paraphrasing) and then measures how much its perplexity changes.
Key Insight:
- Human written text is adaptable and maintains coherence when modified.
- AI generated text is brittle small changes break its logical flow, causing a sharp drop in perplexity.
Example: How Perturbation Affects AI vs. Human Text
| Text Type | Before Perturbation (Log-Likelihood) | After Perturbation (Log-Likelihood) | Likelihood Change | Prediction |
|---|---|---|---|---|
| Human-written | -5.20 | -5.40 | Small Change | Likely Human |
| AI-generated | -3.30 | -6.80 | Large Drop | Likely AI |
By comparing the likelihood of the original and perturbed text, we can confidently classify AI-generated text.
How Perturbation is Applied in AI Detection
The best perturbation methods for breaking AI-generated text include:
| Perturbation Type | Effectiveness | Why It Works? |
|---|---|---|
| GPT Completion Perturbation | Very Strong | Adds AI-generated content, breaking coherence. |
| Text Paraphrasing (T5) | Strong | AI struggles to handle structural changes. |
| Sentence Insertion | Strong | AI-generated text lacks adaptability to new context. |
| Synonym Substitution | Moderate | Small vocabulary changes disrupt AI-generated fluency. |
| Word Shuffling | Weak | AI understands word order well, so minimal impact. |
Conclusion: Why This Matters
1️⃣ AI generated text is predictable (low perplexity), but fragile.
2️⃣ Perturbation disrupts fluency, revealing AI’s inability to adapt.
3️⃣ Large likelihood drops after perturbation indicate AI-generated text.
By combining GPT perplexity with perturbation, AI detection becomes far more accurate, even as models become more advanced.
Perturbation code example
This code defines a Perturbation class that applies various text modifications (perturbations) to assess whether a given text is AI-generated. It leverages GPT-based completion, T5 paraphrasing, synonym substitution, and other techniques to introduce controlled variations in the text and measure how it affects log-likelihood scores. The PerturbationConfig class provides a centralized way to configure model choices, perturbation methods, and randomness, making the system flexible and easy to customize.
import random
import torch
import logging
from nltk.corpus import wordnet
from transformers import AutoModelForSeq2SeqLM, AutoModelForCausalLM, AutoTokenizer, T5Tokenizer
# Configure Logging
logger = logging.getLogger(__name__)
class PerturbationConfig:
"""Configuration class for Perturbation settings."""
def __init__(self):
# Default model settings
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.t5_model_name = "t5-small"
self.gpt_model_name = "EleutherAI/gpt-neo-1.3B"
# Default perturbation method
self.default_method = "gpt_completion" # Change to "random" for randomized perturbations
# Randomization settings
self.use_random_perturbation = False # Set to True to randomize perturbation selection
# Perturbation parameters
self.top_p = 0.92 # Top-p sampling for GPT perturbations
self.paraphrase_top_p = 0.95 # Top-p sampling for T5 paraphrasing
self.max_length = 512 # Max length for generated text perturbations
class Perturbation:
"""Class for perturbing text using different techniques to assess AI-generated text."""
def __init__(self, config: PerturbationConfig = PerturbationConfig()):
self.config = config
self.device = self.config.device
# Load T5 model for paraphrasing
self.t5_model = AutoModelForSeq2SeqLM.from_pretrained(self.config.t5_model_name).to(self.device)
self.t5_tokenizer = T5Tokenizer.from_pretrained(self.config.t5_model_name, model_max_length=512)
# Load GPT model for AI-based text perturbation
self.gptj_tokenizer = AutoTokenizer.from_pretrained(self.config.gpt_model_name)
self.gptj_model = AutoModelForCausalLM.from_pretrained(self.config.gpt_model_name).to(self.device)
logger.info(f"Perturbation class initialized with default method: {self.config.default_method}")
def shuffle_text(self, text):
"""Randomly shuffles words in the text."""
words = text.split()
random.shuffle(words)
perturbed_text = " ".join(words)
logger.debug(f"Shuffle Perturbation: {text} → {perturbed_text}")
return perturbed_text
def remove_word(self, text):
"""Randomly removes a word from the text."""
words = text.split()
if len(words) > 1:
index = random.randint(0, len(words) - 1)
removed_word = words.pop(index)
perturbed_text = " ".join(words)
logger.debug(f"Remove Word Perturbation: Removed '{removed_word}' → {perturbed_text}")
else:
perturbed_text = text
return perturbed_text
def replace_with_mask(self, text):
"""Randomly replaces a word with a mask token."""
words = text.split()
if len(words) > 1:
index = random.randint(0, len(words) - 1)
replaced_word = words[index]
words[index] = "<mask>"
perturbed_text = " ".join(words)
logger.debug(f"Replace Word with Mask: Replaced '{replaced_word}' with '<mask>' → {perturbed_text}")
else:
perturbed_text = text
return perturbed_text
def synonym_substitution(self, text):
"""Replaces words with their synonyms using WordNet."""
words = text.split()
new_words = []
for word in words:
synonyms = wordnet.synsets(word)
if synonyms:
new_word = synonyms[0].lemmas()[0].name()
new_words.append(new_word)
logger.debug(f"Synonym Substitution: Replaced '{word}' with '{new_word}'")
else:
new_words.append(word)
return " ".join(new_words)
def paraphrase_text(self, text):
"""Uses T5 to generate a paraphrased version of the text."""
input_text = f"paraphrase: {text} </s>"
encoding = self.t5_tokenizer.encode_plus(input_text, return_tensors="pt").to(self.device)
with torch.no_grad():
outputs = self.t5_model.generate(**encoding, max_length=self.config.max_length, do_sample=True, top_p=self.config.paraphrase_top_p)
perturbed_text = self.t5_tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.debug(f"Paraphrase Perturbation: {text} → {perturbed_text}")
return perturbed_text
def insert_random_sentence(self, text):
"""Inserts a random unrelated sentence into the text."""
random_sentences = [
"The moon orbits the Earth approximately every 27.3 days.",
"Neural networks have been widely used in deep learning applications.",
"Shakespeare wrote some of the most famous plays in history."
]
random_sentence = random.choice(random_sentences)
words = text.split()
insert_position = random.randint(0, len(words))
words.insert(insert_position, random_sentence)
perturbed_text = " ".join(words)
logger.debug(f"Insert Random Sentence: Inserted '{random_sentence}' → {perturbed_text}")
return perturbed_text
def gpt_completion_perturbation(self, text):
"""Uses a GPT model to generate AI-based perturbations."""
input_ids = self.gptj_tokenizer.encode(text, return_tensors="pt").to(self.device)
with torch.no_grad():
output = self.gptj_model.generate(input_ids, max_length=len(input_ids[0]) + 5, do_sample=True, top_p=self.config.top_p)
perturbed_text = self.gptj_tokenizer.decode(output[0], skip_special_tokens=True)
logger.debug(f"GPT Completion Perturbation: {text} → {perturbed_text}")
return perturbed_text
def perturb_text(self, text, method=None):
"""
Applies the selected perturbation method.
:param text: Input text to be perturbed.
:param method: Name of the perturbation method to apply.
Defaults to the config setting. Use "random" to choose a random method.
:return: Perturbed text.
"""
perturbation_methods = {
"shuffle": self.shuffle_text,
"remove_word": self.remove_word,
"replace_mask": self.replace_with_mask,
"synonym_substitution": self.synonym_substitution,
"paraphrase": self.paraphrase_text,
"insert_sentence": self.insert_random_sentence,
"gpt_completion": self.gpt_completion_perturbation
}
# If no method is provided, use the configured default
if method is None:
method = self.config.default_method
# If configured to use random perturbation, pick one randomly
if method == "random" or self.config.use_random_perturbation:
method = random.choice(list(perturbation_methods.keys()))
if method in perturbation_methods:
logger.info(f"Applying Perturbation: {method} on text: {text}")
return perturbation_methods[method](text)
else:
logger.warning(f"Invalid perturbation method: {method}. Defaulting to GPT Completion.")
return self.gpt_completion_perturbation(text)
Perplexity code example
The GPTPerplexity class is a text analysis tool designed to detect AI-generated text by evaluating the log-likelihood of a sentence using GPT-2 and measuring how this likelihood changes after applying perturbations. The compute_ai_score method assesses the difference between the original and modified text—AI-generated text is typically more fragile, showing a significant likelihood drop after perturbation. The results are encapsulated in the ClassificationResult data structure, which includes the AI score, confidence level, and a final classification of whether the text is “AI-generated” or “Human-written.”
In this example I chose smaller models because of available VRAM.
from dataclasses import dataclass
import torch
import numpy as np
import re
import math
import logging
from transformers import GPT2LMHeadModel, GPT2TokenizerFast, T5Tokenizer
from transformers import AutoModelForSeq2SeqLM
from sklearn.preprocessing import StandardScaler
from scipy.special import erf
# Configure Logging
logging.basicConfig(
filename="gpt_perplexity.log",
filemode="w",
format="%(asctime)s - %(levelname)s - %(message)s",
level=logging.DEBUG
)
logger = logging.getLogger(__name__)
@dataclass
class ClassificationResult:
"""Dataclass to store classification results."""
score: float
diff: float
std_dev: float
confidence: float
label: str
def __str__(self):
"""Custom string representation."""
return f"{self.confidence:.2f}% confidence that the text is {self.label}."
class GPTConfig:
"""Configuration class for GPTPerplexity model settings."""
def __init__(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.gpt_model_id = "gpt2"
self.t5_model_id = "t5-small"
# Perplexity settings
self.max_length = 1024
self.stride = 51
self.threshold = 0.7
# Masking settings
self.mask_span = 2
self.mask_ratio = 0.3
self.mask_samples = 100
# T5 Generation settings
self.t5_top_p = 0.96
self.t5_num_return_sequences = 1
class GPTPerplexity:
"""GPT-based Perplexity and AI-Text Detection Model."""
def __init__(self, config: GPTConfig):
self.config = config
self.device = config.device
# Load models
self.gpt_model = GPT2LMHeadModel.from_pretrained(config.gpt_model_id).to(self.device)
self.tokenizer = GPT2TokenizerFast.from_pretrained(config.gpt_model_id)
self.t5_model = AutoModelForSeq2SeqLM.from_pretrained(config.t5_model_id).to(self.device).half()
self.t5_tokenizer = T5Tokenizer.from_pretrained(config.t5_model_id, model_max_length=512)
# Initialize Perturbation class
self.perturbation = Perturbation(device=self.device)
logger.info("GPTPerplexity Model Initialized.")
def get_log_likelihood(self, sentence):
"""Calculates the log-likelihood of a sentence using GPT2."""
encodings = self.tokenizer(sentence, return_tensors="pt")
seq_len = encodings.input_ids.size(1)
nlls = []
prev_end_loc = 0
for begin_loc in range(0, seq_len, self.config.stride):
end_loc = min(begin_loc + self.config.max_length, seq_len)
trg_len = end_loc - prev_end_loc
input_ids = encodings.input_ids[:, begin_loc:end_loc].to(self.device)
target_ids = input_ids.clone()
target_ids[:, :-trg_len] = -100
with torch.no_grad():
outputs = self.gpt_model(input_ids, labels=target_ids)
nlls.append(outputs.loss * trg_len)
prev_end_loc = end_loc
if end_loc == seq_len:
break
likelihood = (-1 * torch.stack(nlls).sum() / end_loc).cpu().item()
logger.debug(f"Computed log-likelihood: {likelihood}")
return likelihood
def compute_ai_score(self, sentence):
"""Computes an AI-score using log-likelihood differences between original and perturbed texts."""
original_sentence = sentence.strip()
logger.debug(f"Processing sentence: {original_sentence}")
real_log_likelihood = self.get_log_likelihood(original_sentence)
logger.debug(f"Real log-likelihood: {real_log_likelihood}")
# Generate perturbed versions of the sentence
perturbed_sentences = [self.get_log_likelihood(self.perturbation.perturb_text(original_sentence))
for _ in range(self.config.mask_samples)]
logger.debug(f"Perturbed sentances: {perturbed_sentences}")
if not perturbed_sentences:
logger.error("Error perturbing sentences. No valid perturbations.")
return -1
# **Use scikit-learn to standardize data**
scaler = StandardScaler()
all_scores = np.array([real_log_likelihood] + perturbed_sentences).reshape(-1, 1)
standardized_scores = scaler.fit_transform(all_scores).flatten()
logger.debug(f"Standardized Scores: {standardized_scores}")
standardized_real_score = standardized_scores[0]
standardized_perturbed_mean = np.mean(standardized_scores[1:])
standardized_perturbed_std = np.std(standardized_scores[1:])
if standardized_perturbed_std == 0:
logger.warning("Standard deviation is zero. Adding small jitter.")
standardized_perturbed_std = 1e-8 + np.random.uniform(0, 1e-5)
ai_score = (standardized_real_score - standardized_perturbed_mean) / standardized_perturbed_std
logger.info(f"AI Score: {ai_score}, Difference: {standardized_real_score - standardized_perturbed_mean}, Std Dev: {standardized_perturbed_std}")
return float(ai_score), float(standardized_real_score - standardized_perturbed_mean), float(standardized_perturbed_std)
def classify_text(self, sentence) -> ClassificationResult:
"""Classifies text as AI-generated or Human-written and returns a structured result."""
sentence = re.sub(r"\[[0-9]+\]", "", sentence)
score, diff, std_dev = self.compute_ai_score(sentence)
if score == -1 or math.isnan(score):
logger.error("Error: Computed an invalid AI score.")
return ClassificationResult(score=-1, diff=0, std_dev=0, confidence=0, label="Error")
confidence = self.normal_cdf(abs(self.config.threshold - score)) * 100
label = "AI-generated" if score > self.config.threshold else "Human-written"
logger.info(f"Final Classification: {confidence:.2f}% confidence that the text is {label}.")
return ClassificationResult(score=score, diff=diff, std_dev=std_dev, confidence=confidence, label=label)
@staticmethod
def normal_cdf(x):
"""Approximate the CDF of a normal distribution using erf."""
return 0.5 * (1 + erf(x / math.sqrt(2)))
Helper functions
import sqlite3
def setup_database():
"""Creates the SQLite database and results table if it doesn't exist."""
conn = sqlite3.connect("classification_results.db")
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS results (
id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
text TEXT,
score REAL,
diff REAL,
std_dev REAL,
confidence REAL,
label TEXT
)
""")
conn.commit()
conn.close()
def classify_file(model, filename):
"""
Reads a file line by line, classifies each line as 'AI-generated' or 'Human-written',
and stores the results in an SQLite database.
:param model: The GPTPerplexity model for classification.
:param filename: Name of the text file to classify.
"""
print(f"\nProcessing file: {filename}\n" + "-"*40)
with open(filename, "r", encoding="utf-8") as file:
lines = [line.strip() for line in file if line.strip()] # Remove empty lines
if not lines:
print(f"Warning: {filename} is empty or contains only whitespace.")
return
conn = sqlite3.connect("classification_results.db")
cursor = conn.cursor()
for line in lines:
classification_result = model.classify_text(line)
# Insert into the database
cursor.execute("""
INSERT INTO results (filename, text, score, diff, std_dev, confidence, label)
VALUES (?, ?, ?, ?, ?, ?, ?)
""", (filename, line, classification_result.score, classification_result.diff,
classification_result.std_dev, classification_result.confidence, classification_result.label))
print(f" Text: {line}\n {str(classification_result)}\n")
conn.commit()
conn.close()
def generate_markdown_report():
"""Generates a markdown report from the classification results stored in the database."""
conn = sqlite3.connect("classification_results.db")
cursor = conn.cursor()
# Fetch results
cursor.execute("SELECT filename, text, score, confidence, label FROM results")
rows = cursor.fetchall()
conn.close()
# Create Markdown content
markdown_content = "# AI vs. Human Text Classification Report\n\n"
markdown_content += "| Filename | Text | Score | Confidence | Label |\n"
markdown_content += "|----------|------|-------|------------|-------|\n"
for row in rows:
filename, text, score, confidence, label = row
markdown_content += f"| {filename} | {text[:50]}... | {score:.2f} | {confidence:.2f}% | {label} |\n"
# Write to markdown file
with open("classification_report.md", "w", encoding="utf-8") as md_file:
md_file.write(markdown_content)
print("\n Report generated: classification_report.md")
Running the code
# Step 1: Setup the database
setup_database()
# Step 2: Process files and store results in SQLite
config = GPTConfig()
model = GPTPerplexity(config)
classify_file(model, "ai.txt")
classify_file(model, "human.txt")
# Step 3: Generate markdown report from the stored results
generate_markdown_report()
Results using perplexity
- The results here are heavily influenced by the models I used. Because I used smaller models the results were not as strong.
- I increased the threshold from .7 to .4 to stop the models just detecting human text.
- Even so the results are a significant improvement.
AI vs. Human Text Classification Report
| Filename | Text | Score | Confidence | Label |
|---|---|---|---|---|
| ai.txt | “In the ever-evolving landscape of artificial inte… | 0.30 | 53.91% | Human-written |
| ai.txt | “The significance of sustainable energy solutions … | 0.27 | 55.08% | Human-written |
| ai.txt | “The Renaissance was a pivotal period in human his… | 0.76 | 64.04% | AI-generated |
| ai.txt | “Machine learning algorithms leverage vast dataset… | 0.05 | 63.59% | Human-written |
| ai.txt | “Throughout history, civilizations have relied on … | 0.40 | 50.02% | AI-generated |
| ai.txt | “The impact of artificial intelligence on the glob… | 0.48 | 53.23% | AI-generated |
| ai.txt | “While natural language processing has significant… | 0.03 | 64.61% | Human-written |
| ai.txt | “Technological advancements have revolutionized th… | 0.75 | 63.61% | AI-generated |
| ai.txt | “The intricate relationship between data privacy a… | 0.11 | 61.34% | Human-written |
| ai.txt | “Future developments in artificial intelligence ar… | 0.47 | 52.81% | AI-generated |
| human.txt | Honestly, I had no idea AI could write this well u… | 0.14 | 60.40% | Human-written |
| human.txt | I still remember that summer when we stayed up all… | 0.51 | 54.49% | AI-generated |
| human.txt | I tried making sourdough bread last weekend, and l… | -0.09 | 68.94% | Human-written |
| human.txt | Look, I know AI is cool and all, but I still don’t… | -0.06 | 67.63% | Human-written |
| human.txt | You ever get that weird feeling that you left the … | 0.16 | 59.63% | Human-written |
| human.txt | The coffee at that new place on 5th Street is hone… | 0.19 | 58.47% | Human-written |
| human.txt | I can’t explain why, but I really love the sound o… | 0.17 | 58.91% | Human-written |
| human.txt | We spent the whole day hiking, only to realize we … | 0.08 | 62.58% | Human-written |
| human.txt | I swear, my cat understands English but just choos… | -1.09 | 93.17% | Human-written |
| human.txt | Grandma always had the best stories about growing … | -0.75 | 87.52% | Human-written |
Modern LLMs intentionally generate high-perplexity text to sound human. This approach although usable will gradually become ineffective. Also if you use LLM’s a lot you will start to see they are sounding human for longer and longer. Today they can make sentences short blog posts soon they will be writing short books and on.
Sparse Autoencoders and XGBoost
As we have seen the detection cant keep up with the newer models.
To tackle this challenge, we propose a hybrid approach that combines:
Sparse Autoencoders (SAE) for feature extraction from text embeddings
XGBoost for classification of AI vs. Human text
This method provides robust detection by leveraging deep learning for feature learning and gradient boosting for accurate classification.
Why Sparse Autoencoders (SAE) + XGBoost?
| Method | Advantage |
|---|---|
| SAE (Sparse Autoencoder) | Compresses text embeddings into a lower-dimensional representation, learning hidden patterns in AI-generated text |
| XGBoost Classifier | Classifies AI vs. Human text based on extracted SAE features with high accuracy |
This two-step approach allows us to learn meaningful representations of text without explicit supervision while still leveraging a powerful classification algorithm.
Step 1: Collecting Data
For this project, we use the Human vs. Machine dataset from Hugging Face:
from datasets import load_dataset
import pandas as pd
# Load the dataset
dataset = load_dataset("NicolaiSivesind/human-vs-machine")
# Convert to DataFrame
df_train = pd.DataFrame(dataset["train"])
df_test = pd.DataFrame(dataset["test"])
print(f"Training samples: {len(df_train)}, Test samples: {len(df_test)}")
Now, we have a dataset with labeled human and AI-generated text.
Step 2: Generating Text Embeddings
Before feeding text into the SAE, we convert it into embeddings using Ollama’s mxbai-embed-large model.
import torch
import ollama
def get_embedding(text):
"""Generates an embedding using Ollama"""
try:
embedding_data = ollama.embeddings(model="mxbai-embed-large", prompt=text)
return torch.tensor(embedding_data["embedding"], dtype=torch.float32)
except Exception as e:
print(f"Error generating embedding: {e}")
return None
# Convert text to embeddings
train_embeddings = [get_embedding(text) for text in df_train["text"]]
test_embeddings = [get_embedding(text) for text in df_test["text"]]
# Stack embeddings into tensors
train_embeddings_tensor = torch.stack([e for e in train_embeddings if e is not None])
test_embeddings_tensor = torch.stack([e for e in test_embeddings if e is not None])
With our embeddings prepared, we can now extract meaningful features.
Step 3: Training the Sparse Autoencoder (SAE)
The Sparse Autoencoder compresses embeddings to a lower-dimensional feature space while preserving important information.
import torch.nn as nn
import torch.optim as optim
class SparseAutoencoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(SparseAutoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim, input_dim),
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded, encoded
# Initialize model
input_dim = train_embeddings_tensor.shape[1] # Embedding size
hidden_dim = 128 # Feature compression dimension, you may need to adjust
sae = SparseAutoencoder(input_dim, hidden_dim).to("cuda")
# Train SAE
# Define optimizer and loss function
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-5) # Add weight decay for regularization
loss_fn = nn.MSELoss()
epochs = 500
for epoch in range(epochs):
optimizer.zero_grad()
reconstructed, encoded = sae(train_embeddings_tensor.to("cuda"))
loss = loss_fn(reconstructed, train_embeddings_tensor.to("cuda"))
loss.backward()
optimizer.step()
# Compute validation loss
model.eval() # Set to evaluation mode
with torch.no_grad():
val_reconstructed, _ = model(val_embeddings)
val_loss = loss_fn(val_reconstructed, val_embeddings)
# Save best model based on validation loss
if val_loss < best_val_loss:
best_val_loss = val_loss
print(f"Saving best model with validation loss: {best_val_loss.item():.6f} .. {epoch}")
torch.save(model.state_dict(), "best_sparse_autoencoder.pth")
print(f"Epoch [{epoch+1}/{epochs}] - Train Loss: {train_loss.item():.6f} | Validation Loss: {val_loss.item():.6f}")
print("✅ Training completed. Best model saved!")
Now, the SAE learns compact feature representations of text embeddings.
Step 4: Extracting Features Using the SAE
We now use the trained SAE encoder to extract features.
def detect_ai_text(model, test_embeddings, threshold=0.21):
"""
Uses the Sparse Autoencoder to classify AI-generated text.
- Computes reconstruction loss.
- Labels as AI-generated if loss is below threshold.
"""
with torch.no_grad():
reconstructed, _ = model(test_embeddings) # Forward pass through SAE
reconstruction_loss = torch.mean((test_embeddings - reconstructed) ** 2, dim=1) # MSE loss per sample
# Convert to CPU for further processing
reconstruction_loss = reconstruction_loss.cpu().numpy()
# Classify based on threshold
predictions = (reconstruction_loss > threshold).astype(int) # 1 = AI, 0 = Human
return reconstruction_loss, predictions
# Run AI detection on test embeddings
test_reconstruction_loss, test_predictions = detect_ai_text(loaded_model, test_embeddings_tensor)
Now, we have feature vectors ready for classification!
Step 5: Training XGBoost for AI Detection
Using SAE features, we train XGBoost for classification.
import xgboost as xgb
from sklearn.metrics import accuracy_score
# Train XGBoost classifier
xgb_model = xgb.XGBClassifier(
objective="binary:logistic",
eval_metric="logloss",
max_depth=7,
learning_rate=0.01,
n_estimators=500
)
xgb_model.fit(train_features, df_train["label"])
# Predict on test set
test_preds = xgb_model.predict(test_features)
# Evaluate accuracy
accuracy = accuracy_score(df_test["label"], test_preds)
print(f"XGBoost Accuracy: {accuracy:.4f}")
Now, we have a trained AI-text classifier!
Step 6: Visualizing Results
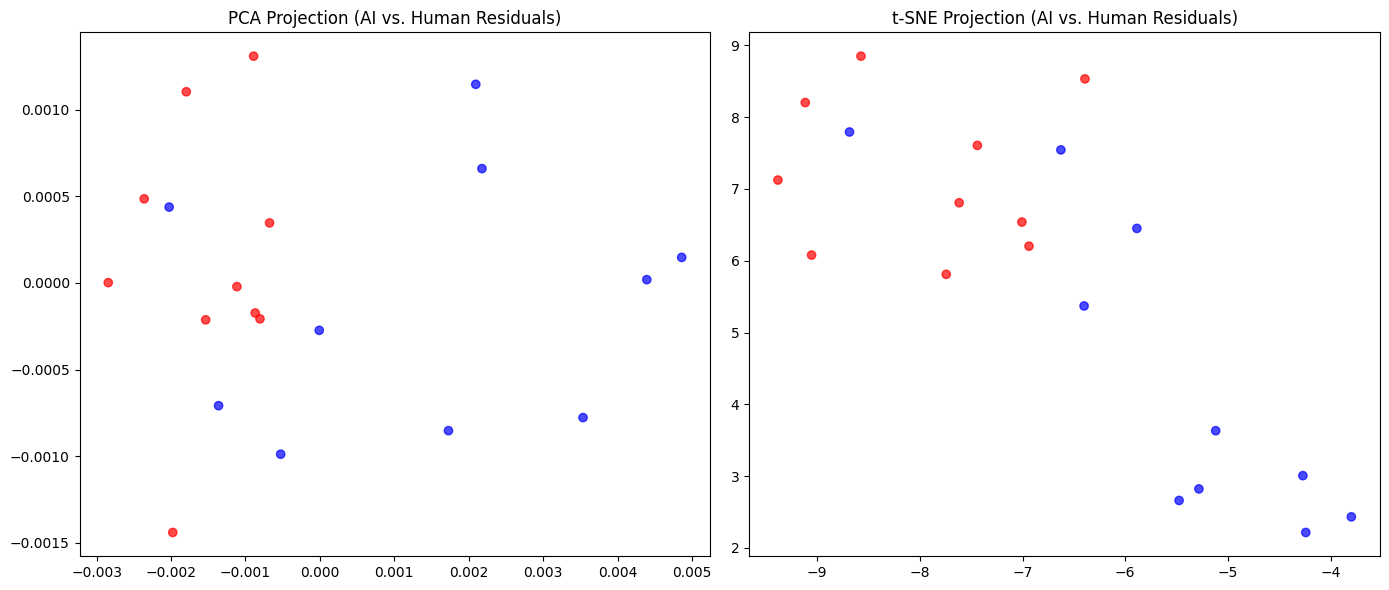
We use t-SNE to check how well the SAE separates AI vs. Human text.
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# Reduce SAE features using t-SNE
tsne = TSNE(n_components=2, random_state=42)
test_features_2d = tsne.fit_transform(test_features)
# Plot results
plt.figure(figsize=(8, 6))
plt.scatter(test_features_2d[df_test["label"] == 0, 0], test_features_2d[df_test["label"] == 0, 1],
c="blue", label="Human", alpha=0.5)
plt.scatter(test_features_2d[df_test["label"] == 1, 0], test_features_2d[df_test["label"] == 1, 1],
c="red", label="AI", alpha=0.5)
plt.xlabel("t-SNE Component 1")
plt.ylabel("t-SNE Component 2")
plt.title(" t-SNE Visualization of SAE Features")
plt.legend()
plt.show()
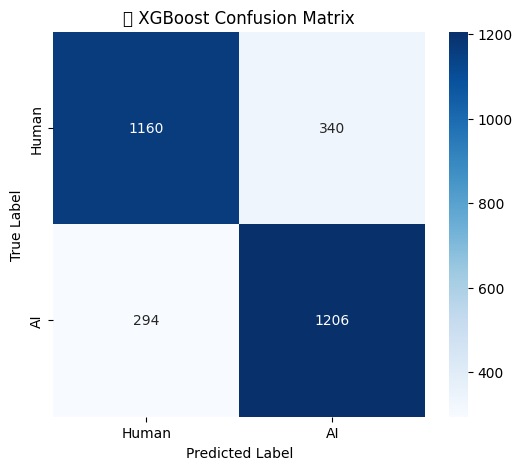
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Compute confusion matrix
cm = confusion_matrix(test_labels, test_preds)
# Plot confusion matrix
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Human", "AI"], yticklabels=["Human", "AI"])
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("📊 XGBoost Confusion Matrix")
plt.show()
Now, we can visually check if AI and Human text embeddings separate well!
Conclusion
By combining Sparse Autoencoders (SAE) for feature learning with XGBoost for classification, we achieve a robust AI-text detection pipeline.
SAE compresses embeddings into meaningful representations
XGBoost leverages these features for high-accuracy classification
The approach generalizes well across AI writing models
This hybrid method is a powerful solution for detecting AI-generated text as LLMs continue to evolve.
Watermarking
As AI-generated text becomes more convincing, watermarking techniques help identify AI-generated content while ensuring security and integrity. Here are the most advanced AI watermarking methods used today.
While watermarking helps identify AI-generated text, it raises questions about privacy and intellectual property.
Probabilistic Watermarking (Token-Level Control)
How it Works:
- AI models slightly modify token probabilities when generating text.
- Some words or token sequences are subtly biased to create a hidden pattern.
- This bias is detectable statistically but remains invisible to humans.
Example:
- A model might favor words like “however” or “indeed” at a higher frequency than usual.
- A secret watermarking key can verify if text contains the pattern.
Real-World Usage:
OpenAI & Anthropic use this technique to watermark ChatGPT and Claude-generated text.
Cryptographic Watermarking (Steganographic Methods)
How it Works:
- AI embeds a unique cryptographic signature in the text.
- It uses word embedding shifts, synonym replacements, or whitespace variations to hide metadata.
- The text can be verified using a decryption key to check if it’s AI-generated.
Example:
- “The quick brown fox jumps over the lazy dog”
- Watermarked: “The swift brown fox leaps over the lazy hound”
- A special algorithm detects this pattern of changes.
Real-World Usage:
Used in Google DeepMind’s AI-generated text detection system.
Style-Based Watermarking (Linguistic Fingerprinting)
How it Works:
- AI intentionally maintains specific writing quirks in sentence structure, word choice, or punctuation.
- A fingerprinting model tracks these patterns to identify AI-generated text.
Example:
- AI often avoids contractions or uses a repetitive sentence rhythm.
- A detector trained on style patterns can predict AI-generated text.
Real-World Usage:
Used by Turnitin AI detection and Hugging Face AI classifiers.
Invisible Character Watermarking (Zero-Width Characters)
How it Works:
- AI inserts invisible Unicode characters (like zero-width spaces or non-printable characters) into the text.
- These characters don’t appear to the human eye but can be detected programmatically.
Example:
- AI-generated text looks normal but contains hidden Unicode sequences like
\u200b(zero-width space). - A script can detect the hidden characters and confirm if text is AI-generated.
Real-World Usage:
Used in Meta AI and Microsoft watermarking solutions for detecting AI text in social media content.
Semantic Watermarking (Meaning-Based Alterations)
How it Works:
- AI slightly rewords sentences while maintaining identical meaning.
- A detector algorithm recognizes the unique phrasing patterns AI models use.
Example:
- Human: “AI is changing the world in unexpected ways.”
- AI (Watermarked): “The world is experiencing unexpected transformations due to AI.”
- The subtle semantic shift is detectable by a trained classifier.
Real-World Usage:
Google’s AI watermarking system uses this in its Bard and Gemini models.
Which Method is Most Effective?
| Watermarking Type | Visibility | Robustness | Use Cases |
|---|---|---|---|
| Probabilistic Token Control | Invisible | Hard to remove | AI chatbot text |
| Cryptographic Watermarks | Hidden | Cryptographically secure | Sensitive AI-generated content |
| Style-Based Fingerprinting | Subtle | Can be bypassed | AI plagiarism detection |
| Zero-Width Characters | Detectable with tools | Easy to remove | AI-written online content |
| Semantic Watermarking | Undetectable | Hard to remove | Journalism & misinformation detection |
Example AI Watermark Detection Script
This Python pipeline will help detect AI-generated text watermarks using multiple watermarking techniques, including:
Probabilistic Token Frequency Analysis
Zero-Width Character Detection
Style-Based AI Fingerprinting
Supports detection for OpenAI, Google, and other AI-generated text.
import re
import numpy as np
import nltk
from nltk.tokenize import word_tokenize
from collections import Counter
from transformers import AutoModelForSequenceClassification, AutoTokenizer
nltk.download("punkt")
class AIWatermarkDetector:
def __init__(self):
"""Initialize token patterns and AI classifiers."""
self.common_ai_tokens = {"thus", "moreover", "indeed", "consequently", "notably"} # Probabilistic watermark
self.tokenizer = AutoTokenizer.from_pretrained("roberta-base-openai-detector")
self.model = AutoModelForSequenceClassification.from_pretrained("roberta-base-openai-detector")
def detect_token_watermark(self, text):
"""Check if AI-preferred words appear more frequently than expected."""
tokens = word_tokenize(text.lower())
token_counts = Counter(tokens)
ai_bias_score = sum(token_counts[token] for token in self.common_ai_tokens if token in token_counts)
normalized_score = ai_bias_score / len(tokens)
return normalized_score > 0.02, f"AI Token Watermark Score: {normalized_score:.4f}"
def detect_zero_width_chars(self, text):
"""Detect invisible Unicode characters that AI models may embed as watermarks."""
hidden_chars = re.findall(r'[\u200B\u200C\u200D\uFEFF]', text) # Zero-width characters
return len(hidden_chars) > 0, f"Zero-Width Characters Found: {len(hidden_chars)}"
def detect_style_patterns(self, text):
"""Use an AI detector model to classify writing style."""
inputs = self.tokenizer(text, return_tensors="pt", truncation=True, padding=True)
outputs = self.model(**inputs)
ai_confidence = outputs.logits.softmax(dim=-1).tolist()[0][1] # AI-generated confidence
return ai_confidence > 0.7, f"Style AI Confidence Score: {ai_confidence:.4f}"
def analyze_text(self, text):
"""Run all detection methods and return the results."""
results = {
"Token Watermark": self.detect_token_watermark(text),
"Zero-Width Watermark": self.detect_zero_width_chars(text),
"Style-Based Fingerprinting": self.detect_style_patterns(text),
}
ai_detected = any(flag for flag, _ in results.values())
final_verdict = "AI-Generated Text Detected" if ai_detected else "Likely Human-Written"
return {"Verdict": final_verdict, "Details": results}
# Usage Example
if __name__ == "__main__":
detector = AIWatermarkDetector()
sample_text = "Indeed, the rapid growth of AI has notably changed how we communicate. Moreover, its impact is undeniable."
result = detector.analyze_text(sample_text)
print(result)
How This Works
- Detects AI-token biases (words that AI prefers like indeed, thus, consequently).
- Checks for zero-width character watermarks (used for AI attribution).
- Uses an AI classifier (RoBERTa) to identify AI writing style patterns.
If any test is triggered, the text is marked as AI-generated.
Running the Detection Script
Run the script with:
python ai_watermark_detector.py
Sample Output:
{
"Verdict": "AI-Generated Text Detected",
"Details": {
"Token Watermark": (True, "AI Token Watermark Score: 0.0345"),
"Zero-Width Watermark": (False, "Zero-Width Characters Found: 0"),
"Style-Based Fingerprinting": (True, "Style AI Confidence Score: 0.8312")
}
}
AI Text Detection Method Comparison
| Method | Strengths | Weaknesses | Best For |
|---|---|---|---|
| RoBERTa Detector | Fast, Pre-trained | Poor against GPT-4+ | Basic AI text detection |
| Perplexity + Perturbation | Exposes brittle AI writing | Requires tuning for each model | Detecting AI fluency patterns |
| Sparse Autoencoders + XGBoost | Learns hidden AI patterns | Needs large dataset | Model-agnostic AI detection |
| AI Watermarking Detection | Can verify AI text with certainty | Only works if watermark exists | Identifying marked AI content |
Code and further examples
The code used while writing and researching this post can be found here:
References
1️⃣ Feature-Level Insights into Artificial Text Detection with Sparse Autoencoders 2️⃣ NicolaiSivesind/human-vs-machine 3️⃣ Multiscale Positive-Unlabeled Detection of AI-Generated Texts 4️⃣ gpt-2-output-dataset 5️⃣ DetectGPT
Conclusion
Looking at the results, AI detection still has a significant margin of error. As models improve, the distinction between AI-generated and human-written text will blur even further. In the future, it may be impossible to say with certainty whether a piece of text was written by a machine or a person.
The reality of AI? It’s all about probabilities estimations, not certainties. Every detection method, from perplexity and perturbation to sparse autoencoders, relies on probability scores. But as LLMs like GPT-4o and Claude advance, even the best detection techniques are beginning to struggle.
🔹 The Inevitable Rise of AI-Generated Content
Instead of fighting AI-generated text, we should focus on how to use AI effectively. AI is not a threat to creativity it is a tool for amplification.
The best approach? Use AI to generate content, then rewrite it in your own voice. If a human adds their own insights, experiences, and emotions, can we still call it AI-generated? Or is it simply enhanced human writing?
🔹 The Future of Writing: AI + Human Synergy
🔹 AI isn’t replacing human creativity it’s evolving it.
🔹 Detection will become harder, but authenticity will remain in human expression.
🔹 The key isn’t avoiding AI, but learning how to use it in a way that enhances rather than replaces originality.
So instead of asking whether text is AI-generated, perhaps the better question is: How do we use AI to create something uniquely ours?
The real question about a piece of work or art isn’t how it was created, but whether you find it useful or meaningful.
Use it. Improve it. Make it yours.
Glossary
| Term | Definition |
|---|---|
| RoBERTa Detector | A pre-trained AI model that classifies whether text is AI-generated or human-written. |
| Perplexity | A measure of how predictable a text is; AI-generated text often has lower perplexity because it follows structured patterns. |
| Perturbation | A technique where text is slightly modified (e.g., paraphrasing, inserting words) to see if AI-generated text breaks under small changes. |
| Sparse Autoencoder (SAE) | A machine learning model that learns a compressed representation of text features, helping to distinguish AI-generated patterns. |
| XGBoost | A gradient boosting machine learning algorithm used for classification; it helps detect AI-generated text by analyzing features extracted by the SAE. |
| Watermarking | A method where AI models embed hidden markers in generated text to later verify whether it was created by AI. |
| AI-Generated Text | Any text produced by AI models rather than humans, often trained to mimic human style and fluency. |
| Zero-Width Watermarking | A technique where invisible Unicode characters (e.g., zero-width spaces) are inserted in AI text for detection. |
| Cryptographic Watermarking | A security method where AI text is digitally signed with cryptographic markers that can be later verified. |